10.08.2023
1. MINIST
MNIST는 기계학습의 기본적이고 유명한 7만개의 수기로 쓴 0부터 9까지의 정수 이미지 데이터셋이다.
사이킷런에서는 이 데이터셋을 다운로드 받을 수 있도록 제공하고 있다.
각 인스턴스는 하나의 행이며, 각 피쳐가 하나의 컬럼이 된다.
이 데이터셋의 경우, 하나의 이미지는 784개의 피쳐를 가지고 있다.(28*28 픽셀이기 때문)
하나의 피쳐는 각 픽셀의 intensity를 의미한다. (0-255)
MINIST데이터셋은 이미 트레이닝 데이터와 테스트 데이터로 나뉘어져 있다(6만, 1만)
그리고 이미 균형잡히게 섞여져 있음. 만약 그렇지 않다면 전체 파퓰레이션 반영을 못하게 되므로 셔플이 잘 되어있어야 함.
2. Training a Binary Classifier
이제부터 문제를 바이너리로 단순화 시켜야 한다. -> 하나의 숫자만 특정하도록 하자. (5라고 가정)
다음은 타겟 발류를 잡는 코드이다.

2-1. Stochastic Gradient Descent(SGC) classifier
Optimal value(최적값)을 찾아가는 방법 중 하나이다.
큰 데이터셋을 핸들링할 수 있다는 장점이 있고, 트레이닝 인스턴트를 독립적으로 다루기 때문에 온라인 러닝에 적합하다.

3. Performance Measures
클래시피케이션 문제에서는 성능 측정이 굉장히 중요하다.
3-1. Cross-Validation을 통해 정확도 측정하기
먼저 사이킷런으로 cross_val_score()을 통해 정확도를 측정해보도록 하자.

cross_val_score(클래시파이어, 입력데이터, 타겟데이터, cross validation fold 갯수, 측정을 원하는 성능 종류)
측정을 세번 했기 때문에 결과 array의 length는 3이며, 적어도 93퍼 이상의 정확도를 갖는다. 다만 정말일까?
모든 이미지를 "5가 아니다"라고 분류하는 굉장히 멍청한 클래시파이어를 만들었다고 가정해보자.

이렇게 멍청한 클래시파이어도 적어도 90프로 이상의 정확도를 가진다. 전체 데이터의 90프로는 5가 아니기 때문이다.
이러한 예제를 통해 정확도 측정이 성능 측정으로써 옳은 선택인가? 라는 의문을 가지게 된다.
결론적으로 클래시피케이션 문제를 풀 때는, 특히 skewed datasets(몇개의 클래스들이 다른 클래스들보다 훨씬 많은(frequent) 데이터셋)을 다룬다면, 정확도를 이용해 성능을 측정하는 것이 선호되지 않는다.
그렇다면 대안 방법으로는 무엇이 있을까?
3-2. Confusion Matrix(혼동 행렬, 오차 행렬)
컨퓨전 매트릭스를 보는 것이 클래시파이어 성능 측정에는 더 좋다.

confusion_atrix(Ground Truth Label, 예측값들)

row: 실제 클래스
column: 예측 클래스
True Negatives: 5가 아닌 것들을 5가 아니라고 잘 분류, 53057
False Positives: 5가 아닌 것들을 5라고 분류, 1522
Flase Negatives: 5인 것들을 5라고 분류, 1325
True Positives: 5인 것들을 5라고 잘 분류, 4096
완벽한 클래시파이어가 있다면 오직 true positives, true negatives만을 가질 것이지만, 이런 경우가 나올 수도 없고 나와서도 안된다.
이런 경우는 오버피팅된 클래시파이어가 나왔다고 판단되기 때문
3-2. Precision and Recall
positive predictions의 정확도를 보면 precision(정밀도) of the classifier 을 알수 있다.
정밀도는 보통 recall, sensitivity, or true possitive rate이라고 불리는 다른 매트릭스와 함께 사용된다.


컨퓨전 매트릭스 예시
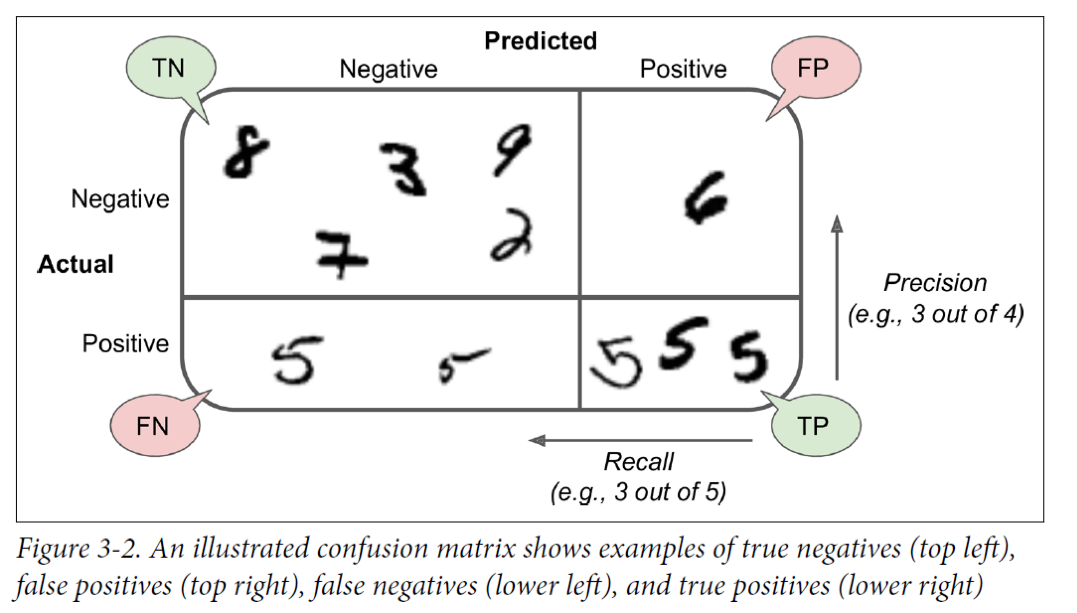
프리시젼: 예측한것 중에 몇 개를 잘 맞췄는지
리콜: 실제 맞는 값 중에 몇 개를 잘 맞췄는지
사이킷 런은 프리시젼과 리콜을 포함한 클래시파이어 매트릭스를 계산하기 위한 함수들을 제공한다.

프리시전: 5라고 클레임 한 것들 중 진짜 5는 72퍼
리콜: 진짜 5중에서 75퍼밖에 판별을 못했다
프리시전과 리콜은 트레이드오프 관계에 있다. 더 편하게 결과를 보기 위해서 F1 score라고 불리는 매트릭스로 precision과 recall을 컴바인한다.

프리시전과 리콜은 비슷한 수준으로 해야 좋은 레퍼런스 코어를 가질 수 있음.
그러나 둘 중 하나를 더 우선시해야하는 경우는 문맥에 따라 달라진다.
만약 아동 유해물 디텍터를 만든다고 했을때, false negative보다(유해물이 아닌데 유해물이라고 선정)false positive(유해물인데 유해물이 아니라고 선정)를 낮추는게 더 중요해짐
다른 예로 도둑 감지기를 만든다고 했을때, false positive보다(안들었는데 들어왔다고 탐지)false negative(들어왔는데 안들어왔다고 탐지)를 낮추는게 더 중요함
Precision/Recall 관계에서 Trade-off가 생기는 이유

위 사진을 보면 애매한 존에서 쓰레스홀드가 생기는 것을 볼 수 있다.
이 쓰레스홀드의 위치가 리콜/프리시전 트레이드 오프를 결정한다.
플랏을 이용해서 원하는 쓰레스홀드를 찾는 것은 분량상 스킵하도록 하겠다.
3-2. The ROC curve
ROC curve: The Receiver Operating Characteristic curve
바이너리 클래시파이어와 사용할 수 있는 또 다른 툴이다.
ROC는 flase positive rate(FPR)에 대한 true positive rate rate(recall)을 plot해준다. (2차 함수 그래프로 만들어준다)
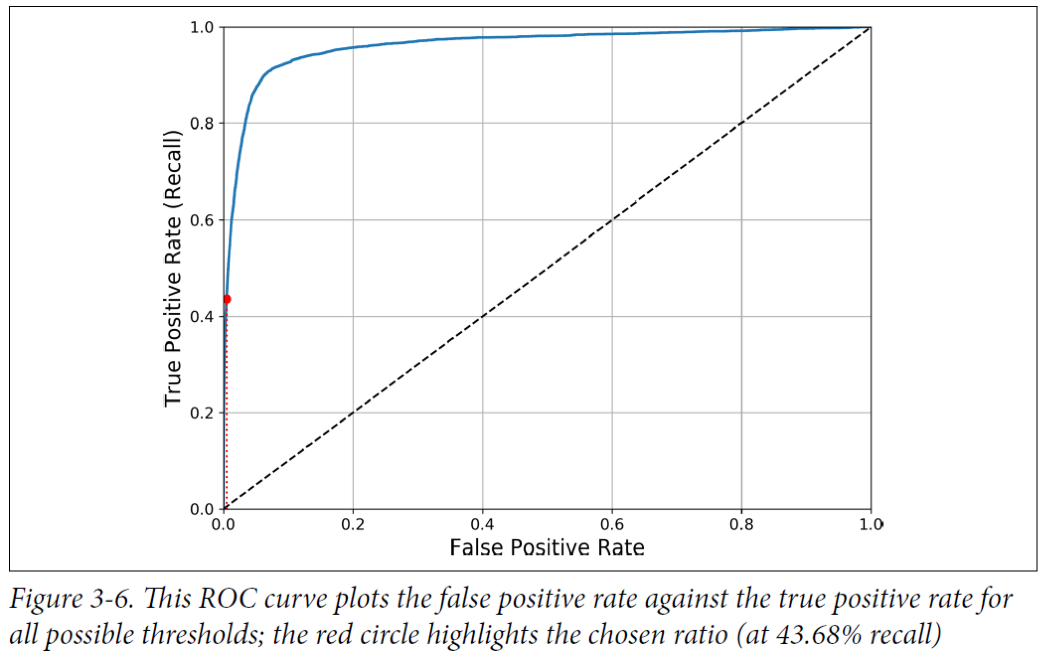
그래프가 top-left 코너쪽으로 최대한 끌어올려져야 좋다
4. Multiclass Classification
바이너리 클래시파이어는 두개의 클래스 사이에서 구별되는 반면, 멀티 클래시파이어는 3개 이상의 클래스 사이에서 구별된다.
로지스틱 리그레션, 랜덤 포레스트, 나이브 베이즈(navie Bayes) 등과 같은 알고리즘은 멀티 클래시피케이션 다루기 가능.
그러나 이런 알고리즘을 제외한 다른 알고리즘들(SGD, Support Vector Machine 등)은 바이너리만 지원한다.
다행히도, 이런 알고리즘을 쓸 때 멀티 클래시피케이션을 사용하기 위한 전략들이 존재한다.
4-1. OvR(one-versus-the-rest, one-versus-all) strategy
0-9를 판단하는 이미지 클래시피케이션을 한다고 가정했을때 클래스는 10개이다.
이때 각 클래스에 대한 decision score 얻어 가장 높은 디시젼 스코어를 가진 클래스를 선택한다.
4-2. OvO (one-versus-one) Strategy
모든 숫자 페어에 대해 바이너리 클래시파이어를 학습시킨다. (0/1, 1/2, 1/2, ... 8/9)
이때 트레이닝의 횟수는 N*(N-1)/2가 된다.
이경우에는 45개의 클래시파이어가 생성되며, 가장 많은 듀얼을 이룬 클래스가 선택된다.
OvO의 장점은 각 클래시파이어는 트레이닝 되어야하는 데이터들에 대해서만 학습된다는 점이다.
스케일이 트레이닝 셋 사이즈에 대해서 성능이 잘 안나오는 알고리즘의 경우(Support Vector Machine)만 OvO가 선호된다.
대부분의 바이너리 클래시피케이션 알고리즘에는 OvR이 더 좋다.

5. Error Analysis
에러 분석은 Confusion Matric를 통해 할 수 있다.

0번째 로우 0번째 컬럼이 94프로라는 뜻은 94퍼센트의 0 이미지가 0으로 분류되었고, 나머지 1,1,4퍼의 0 이미지는 각각 5,6,8로 분류되었다는 뜻이다.
클래시파이어는 이미지 쉬프팅과 로테이션에 민감하다.
이미지를가 잘 센터되었는지, 너무 로테이트 되진 않았는지 ensure하기 위해 이미지를 정제, 정규화 한다면 에러가 줄어들 수 있다.
6. Multilable Classification
이 경우는 하나의 이미지에 여러가지 사물이 있어 여러개의 레이블이 있는 경우를 다룬다.
멀티레이블 클래시파이어를 평가하는 방법은 많고, 무엇이 맞는 것인지는 프로젝트에 따라 다르다.
하나의 방법으로는 F1 스코어를 각 레이블에 대해 메쥬어한 다음 에버레이지 스코어를 계산하는 것이다.

SVC와 같이 원래 멀티레이블을 서포트하지 않는 클래시파이어를 사용하고 싶다면, 하나의 모델당 하나의 레이블을 학습시키면 될 수 있다.
이런 경우, 레이블들 사이의 의존성을 잡기 어려울 수 있다.
해결방법으로, 모델들을 체인으로 만드는 방법이있다. 모델이 프리딕션을 할때, 체인이 인풋피쳐와 모델들의 프리딕션을 이용하는 것.
7. Multioutput Classification
멀티 아웃풋 클래시피케이션은 멀티클래스 분류의 확장버전이라고 할 수 있다.
멀티 아웃풋 클래시피케이션에서는 한 데이터에 여러 레이블, 여러 클래스가 존재하고 그 클래스들도 여러개의 값을 가진다.
하나의 레이블이 여러개의 값을 가지기 때문에 멀티 아웃풋 클래시피케이션이라 부른다.
'CS > ML' 카테고리의 다른 글
| [ML] 요점정리 (1) | 2023.10.25 |
|---|---|
| [ML] 5주차 - SVM (1) | 2023.10.23 |
| [ML] 4주차 - 트레이닝 모델 (1) | 2023.10.22 |
| [ML] 머신러닝 2주차 복습 정리 (1) | 2023.10.01 |
| [ML] 머신러닝 1주차 복습정리 (0) | 2023.09.17 |


